Gemma 4 26B API vs Self-Hosted: The Honest Infrastructure Cost Guide
Gemma 4 26B API vs Self-Hosted: The Honest Infrastructure Cost Guide
You've decided Gemma 4 26B is the right model for your product. Smart choice. Now comes the question that every startup developer eventually sits down to figure out: how do you actually run it?
You have two obvious paths. Pay a cloud API provider per token. Or rent your own GPU server and host it yourself. Both sound reasonable on paper. Both have serious hidden costs that only show up after you've committed to one.
This guide gives you the honest breakdown of both paths — and a third option most developers don't know about yet.
1. The Deployment Crossroads
Google DeepMind released Gemma 4 26B in April 2026 under Apache 2.0 — fully free for commercial use. The model has a clever design: it carries 26 billion parameters on disk, but only 3.8 billion activate per response. Think of it like a factory floor with 128 specialist stations — for each job, only the relevant 8 stations light up. Everything else stays dark and quiet.
The result is a model that thinks like something much larger but moves at the speed of something much smaller. That speed is what makes it viable on consumer-grade hardware. It's also what makes the infrastructure decision genuinely interesting, because you have more options than you'd have with a traditional dense model.
So which path is right for your product?
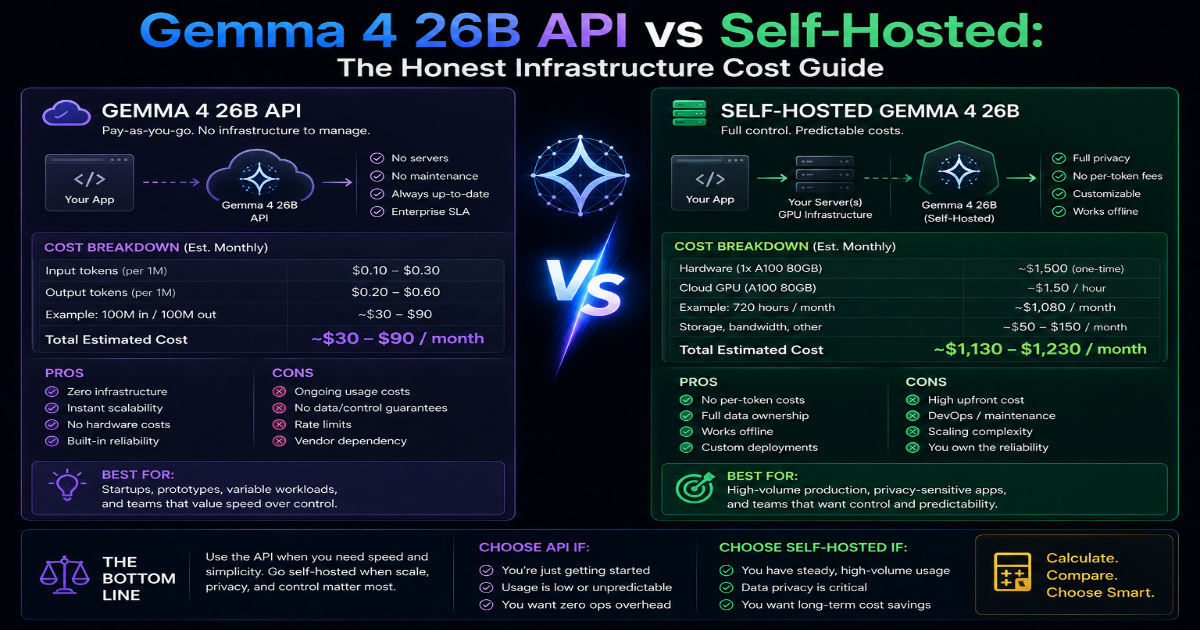
2. Option A — The Serverless Cloud API Path
This is the route most developers start with. You sign up with a managed API provider, get a key, and start sending requests. You pay a small fee for every million tokens your app processes — typically around $0.15 per million input tokens and $10–$15 per million output tokens depending on the provider.
Why It's Attractive
Zero setup. No Linux server configuration. No driver installation. No GPU memory tuning. You paste a base_url and an API key into your code and you're running in minutes. For prototyping and early-stage validation, that speed of setup is genuinely valuable.
Automatic scaling. If your product suddenly gets a thousand concurrent users, the provider's infrastructure absorbs the spike. You don't page anyone at 2 AM because a server ran out of memory.
The Hidden Costs
Privacy exposure. Every prompt you send travels over the public internet to someone else's server, gets processed there, and returns. For internal tools, customer support systems, or anything that touches personal data — this is a compliance problem. GDPR, HIPAA, SOC 2 — all of these frameworks have opinions about where customer data goes and who processes it.
The Thinking Tax. This is the one that catches most teams off guard.
Gemma 4 26B has an extended thinking mode that activates automatically on hard problems. Before it gives you an answer to a complex coding task or a multi-step agent decision, it generates thousands of internal reasoning tokens — a scratchpad it uses to work through the problem. You never see these tokens. They don't appear in your output.
But a pay-per-token API charges you for every single one.
Real example: You send a 10,000-token code review request. The model generates 6,000 thinking tokens + 800 tokens of actual output. You're billed for 16,800 tokens but received 800 tokens of useful content. At $15/million output tokens, that's $0.25 per request. An agent running 500 reviews per day = $125/day = $3,750/month — primarily on tokens you never read.
For occasional use, the per-token model is fine. For agents, loops, and production workloads, the math breaks fast.
3. Option B — The DIY Self-Hosted Path
The natural response to token anxiety is: "I'll just host it myself." You rent a GPU server — an NVIDIA A100 or H100 on a raw cloud provider — load the model weights using vLLM, and run your own inference endpoint. No token markups. Your data never leaves your network.
Why It's Appealing
Full data sovereignty. Everything stays inside your own Virtual Private Cloud (VPC). Customer data, internal code, sensitive documents — none of it touches a third-party server. For teams under strict security compliance, this is often a hard requirement, not a preference.
No per-token billing. Once the server is running, you can process 10 million tokens or 10 billion tokens — the cost doesn't change. For high-volume workloads, this is a fundamentally better economics model.
The Brutal Realities
Idle billing never sleeps. A dedicated GPU server charges you the same hourly rate at 3 AM on a quiet Tuesday as it does at peak noon traffic. Gemma 4 26B at full precision needs at least a 24 GB GPU, and those aren't cheap. An RTX A6000 or A100 runs $2–$4/hour on most cloud providers — $48–$96/day even when nobody is using your product.
Cold start warning: Loading
Gemma 4 26Bweights from disk onto a fresh GPU takes 30 to 90 seconds. If you scale down to zero overnight to save costs and then scale back up in the morning, every first user of the day waits 60+ seconds for a response. That's not an acceptable experience for any production app.
The vLLM configuration rabbit hole. Getting Gemma 4 26B's 128-expert MoE architecture running correctly is not a one-afternoon task. A naive configuration will push peak VRAM usage above 48 GB — far beyond a single GPU. The stable configuration requires:
# vLLM config for Gemma 4 26B MoE — minimum viable setup
model: google/gemma-4-26B-A4B-it
tensor_parallel_size: 2
max_model_len: 131072
gpu_memory_utilization: 0.90
enable_chunked_prefill: true
max_num_batched_tokens: 8192
Two GPUs. Manual chunked prefill. Utilization tuning. And that's before you've set up health checks, auto-restart scripts, load balancing, or monitoring. This is a part-time infrastructure job added to your team's plate — indefinitely.
Maintenance reality check: Most small engineering teams that go self-hosted report spending 20–30% of their infrastructure engineering time on model server maintenance rather than product features. That's the true cost that never appears in a cost comparison spreadsheet.
4. The Smart Alternative — OpenLLM Buddy
OpenLLM Buddy occupies the space between these two options — and it's the position that makes the most sense for the majority of startup teams.
Think of it this way: Option A is renting a hotel room (convenient, but you pay premium rates and share the building). Option B is building your own house (total control, but months of construction and ongoing maintenance). OpenLLM Buddy is a fully furnished private apartment — your own space, ready on day one, with someone else handling the plumbing.
What the Platform Does
It gives you a pre-configured, OpenAI-compatible API endpoint running Gemma 4 26B on dedicated NVIDIA RTX 4090 and RTX 5090 hardware via RunPod compute. The full MoE expert routing, KV cache management, and VRAM optimization are handled at the platform level. You get the clean endpoint. You skip the configuration nightmare.
No cold-start delays. No tensor parallelism tuning. No 3 AM server crash pages.
The Core Value Proposition
Token consumption is 100% free. You pay only for GPU compute time.
No input token charge. No output token charge. No thinking token charge. That 6,000-token reasoning chain that costs you $0.09 per request on a serverless API? On OpenLLM Buddy, it costs the same as every other request — nothing extra.
Pricing that's predictable from day one:
| Plan | Gemma 4 26B (RTX 4090) | Qwen 3.6 27B (RTX 5090) |
|---|---|---|
| 11 Hours | $10 | $14 |
| 24 Hours | $22 | $31 |
| 1 Week | $150 | $212 |
| 1 Month | $599 | $845 |
Both plans auto-terminate on uptime quota — no idle overnight billing when your users go to sleep.
Connecting your existing application is one line:
import openai
# Route your Gemma 4 workflow to token-free cloud hardware
client = openai.OpenAI(
base_url="https://api.openllmbuddy.cloud/v1",
api_key="YOUR_OPENLLM_BUDDY_KEY"
)
response = client.chat.completions.create(
model="gemma-4-26b-a4b",
messages=[{"role": "user", "content": "Your prompt here"}],
temperature=0.1
)
The base_url is the only change. Every other line of your code — your prompts, your tools, your agent logic — stays identical.
The Honest Decision Framework
Here's a plain summary to make the choice simple:
| Situation | Best Path |
|---|---|
| Early prototype, < 100 requests/day | Serverless API (keep it simple) |
| High-volume agents, 1,000+ calls/day | OpenLLM Buddy (flat rate wins) |
| Strict compliance, data must stay internal | OpenLLM Buddy or self-hosted VPC |
| Team has dedicated DevOps bandwidth | Self-hosted (if you can maintain it) |
| Small team, no infrastructure headcount | OpenLLM Buddy (skip the ops work) |
The serverless API path is the right answer for early validation. The moment your workload starts generating serious token volume — or the moment your agents start using extended thinking mode heavily — the economics shift decisively toward flat-rate compute.
OpenLLM Buddy is where most production teams land when they run that math. Swap the base_url. Keep the code. Drop the token bill.


