Create an AI Customer Support Agent Without OpenAI APIs: The Definitive Open-Source Blueprint
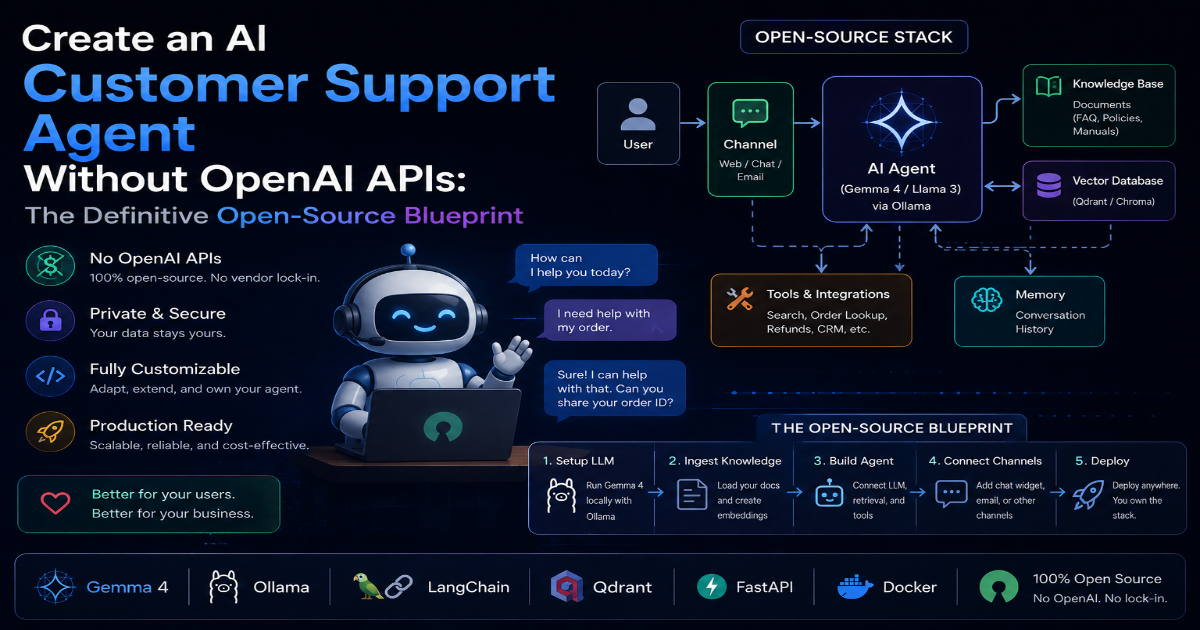
Create an AI Customer Support Agent Without OpenAI APIs
What you'll build: A customer support agent that works on its own. It uses Qwen 3.6 27B or Gemma 4 26B, FastAPI, and LangChain. No OpenAI needed. No surprise token bills. Your data stays with you.
1. Why Move Away from OpenAI?
More engineering teams are leaving closed API ecosystems. Here's why:
You get locked in. When your whole support system depends on one company, every change they make affects you. OpenAI has removed older models like gpt-3.5-turbo with only 90 days notice. Each time, teams had to rush to fix their systems.
Models change without telling you. Closed models update silently. The gpt-4o you tuned in March works differently in September — same name, different behavior. Your support agent that was 94% accurate drops to 87% with no warning.
Compliance is harder. Every customer message sent to a third-party API is a risk. GDPR, HIPAA, SOC 2 — all of these become problems when customer data leaves your network. With self-hosted open models, your data never leaves your control.
Billing is unpredictable. Support conversations get longer. A thread that reaches 15 turns makes you re-send the whole history every time. Token bills that look fine at 100 tickets/day become a nightmare at 5,000 tickets.
The Better Option: Apache 2.0 Open Models
Qwen 3.6 27B and Gemma 4 26B-A4B both use Apache 2.0 license. That means:
- No limits on how many people use it
- No audits for acceptable use
- Full rights to use it in commercial products
Both models match closed systems on multi-turn conversations, calling tools, and outputting structured JSON — exactly what a support agent needs.
2. System Architecture — How It Works
The Ingestion Layer (Receiving Tickets)
Your entry point is a FastAPI backend that accepts ticket data:
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import Optional
app = FastAPI()
class SupportTicket(BaseModel):
ticket_id: str
customer_id: str
session_id: str # links to conversation state
message: str
channel: str # email | chat | api
priority: Optional[str] = "normal"
@app.post("/support/ingest")
async def ingest_ticket(ticket: SupportTicket):
# Get or create conversation history
history = await state_store.get(ticket.session_id) or []
# Run the agent
response = await run_support_agent(ticket, history)
# Save updated history
await state_store.set(ticket.session_id, response["updated_history"])
return {"reply": response["agent_reply"], "actions_taken": response["actions"]}
Pydantic validation checks data at the door. Bad data never reaches the model.
Storing Conversation State
Support conversations have memory. A customer reporting a shipping issue at turn 1 shouldn't have to re-identify themselves at turn 8. Use Redis to store sessions:
import redis.asyncio as redis
import json
redis_client = redis.Redis(host="localhost", port=6379, decode_responses=True)
async def get_history(session_id: str) -> list:
raw = await redis_client.get(f"support:session:{session_id}")
return json.loads(raw) if raw else []
async def set_history(session_id: str, history: list, ttl_hours: int = 48):
await redis_client.setex(
f"support:session:{session_id}",
ttl_hours * 3600,
json.dumps(history)
)
The conversation history follows a standard format — works with any OpenAI-compatible endpoint including OpenLLM Buddy:
history = [
{"role": "system", "content": SUPPORT_SYSTEM_PROMPT},
{"role": "user", "content": "Where is my order #ORD-8821?"},
{"role": "assistant", "content": "Let me check that order status for you."},
{"role": "tool", "content": '{"status": "in_transit", "eta": "2026-06-02"}', "tool_call_id": "call_abc123"},
{"role": "user", "content": "Can you expedite it?"}
]
The Tool Registry (Letting the Agent Take Action)
This is where the agent can actually do things — not just reply. Define tools with clear instructions:
SUPPORT_TOOLS = [
{
"type": "function",
"function": {
"name": "query_order_db",
"description": "Look up current order status, delivery date, and tracking number.",
"parameters": {
"type": "object",
"properties": {
"order_id": {"type": "string", "description": "e.g. ORD-8821"},
"customer_id": {"type": "string", "description": "Customer UID if no order ID"}
},
"required": []
}
}
},
{
"type": "function",
"function": {
"name": "issue_refund",
"description": "Start a refund. Only use if customer asks and order qualifies.",
"parameters": {
"type": "object",
"properties": {
"order_id": {"type": "string"},
"reason": {
"type": "string",
"enum": ["damaged", "not_delivered", "wrong_item", "customer_request"]
},
"amount": {"type": "number", "description": "Refund amount in USD"}
},
"required": ["order_id", "reason"]
}
}
},
{
"type": "function",
"function": {
"name": "escalate_to_human",
"description": "Send conversation to a human. Use when customer is upset or issue can't be solved.",
"parameters": {
"type": "object",
"properties": {
"reason": {"type": "string"},
"priority": {"type": "string", "enum": ["normal", "urgent", "critical"]}
},
"required": ["reason", "priority"]
}
}
}
]
Guardrail Layer — Check Every Output
For structured actions (like issuing refunds), use constrained decoding to guarantee valid output:
from pydantic import BaseModel
from typing import Literal, Optional
class AgentAction(BaseModel):
action_type: Literal["reply", "tool_call", "escalate", "resolve"]
reply_text: Optional[str] = None
tool_to_call: Optional[str] = None
tool_arguments: Optional[dict] = None
resolution_code: Optional[str] = None
escalation_priority: Optional[Literal["normal", "urgent", "critical"]] = None
# Check every output before using it
def validate_agent_output(raw_output: str) -> AgentAction:
try:
return AgentAction.model_validate_json(raw_output)
except Exception as e:
# If validation fails, escalate safely
return AgentAction(
action_type="escalate",
escalation_priority="normal",
tool_arguments={"reason": f"Output validation failed: {str(e)}"}
)
Validating every turn means bad model output never corrupts your data or accidentally issues a refund.
3. The Real Cost Problem — Context Bleeding
Here's what most guides don't tell you.
A real support conversation doesn't end in one turn. Look at a typical workflow:
- Turn 1 — Customer says order is missing. Agent checks order DB. (Adds ~800 tokens to history)
- Turn 3 — Customer asks about refund policy. Agent finds policy doc. (Adds ~1,200 tokens)
- Turn 5 — Customer asks for refund. Agent calls
issue_refund. (Adds ~400 tokens) - Turn 7 — Customer asks for email confirmation. Agent checks profile. (Adds ~300 tokens)
- Turn 8 — Done.
By turn 8, the context window has the system prompt, 8 conversation turns, 4 tool results, and all reasoning. That's 8,000–12,000 tokens of history being processed on every call from turn 4 onward.
With a pay-per-token API at $15/million tokens: a single 8-turn support thread costs $0.18–$0.27 just to read the history. At 1,000 tickets/day, that's $180–$270/day — $5,400–$8,100/month. For one support workflow.
The problem gets worse with longer conversations. A 50,000-token conversation history costs $0.75 per additional turn just to re-read everything.
Self-hosting isn't free either. Running these models on unmanaged cloud requires:
- Manual setup of
vLLMacross multiple GPUs - Custom load balancing for traffic spikes
- Paying for idle GPUs at 3 AM when no tickets come in
- 30–90 second delays when scaling up — terrible for live chat
4. Production Scale — Zero Token Bills with OpenLLM Buddy
OpenLLM Buddy solves both problems at once.
It gives you a ready-to-use, OpenAI-compatible endpoint for Qwen 3.6 27B and Gemma 4 26B on dedicated NVIDIA RTX 4090 and RTX 5090 hardware. No setup. No config files. No idle billing.
Token consumption is 100% FREE. You pay only for GPU compute time.
No charge for input tokens. No charge for output tokens. No re-reading tax on turn 8. Your 50,000-token history on turn 50 costs the same flat rate as everything else.
Connect Your Support Agent to OpenLLM Buddy
Switching from any OpenAI-compatible stack is just changing the base_url:
from openai import OpenAI
# Token-free infrastructure
client = OpenAI(
base_url="https://api.openllmbuddy.cloud/v1",
api_key="YOUR_OPENLLM_BUDDY_KEY"
)
async def run_support_agent(ticket: SupportTicket, history: list) -> dict:
# Add new customer message
history.append({"role": "user", "content": ticket.message})
response = client.chat.completions.create(
model="qwen-3.6-27b", # or "gemma-4-26b-a4b"
messages=history,
tools=SUPPORT_TOOLS,
tool_choice="auto",
temperature=0.1,
max_tokens=1024
)
message = response.choices[0].message
# Handle tool calls if needed
if message.tool_calls:
for tool_call in message.tool_calls:
tool_result = await execute_tool(
tool_call.function.name,
json.loads(tool_call.function.arguments)
)
history.append({"role": "tool", "content": json.dumps(tool_result), "tool_call_id": tool_call.id})
# Second pass — process tool results
follow_up = client.chat.completions.create(
model="qwen-3.6-27b",
messages=history,
temperature=0.1,
max_tokens=512
)
agent_reply = follow_up.choices[0].message.content
else:
agent_reply = message.content
history.append({"role": "assistant", "content": agent_reply})
return {"agent_reply": agent_reply, "updated_history": history, "actions": message.tool_calls or []}
Simple, Predictable Pricing
| Plan | Qwen 3.6 27B (RTX 5090) | Gemma 4 26B (RTX 4090) |
|---|---|---|
| 11 Hours | $14 | $10 |
| 24 Hours | $31 | $22 |
| 1 Week | $212 | $150 |
| 1 Month | $845 | $599 |
Both plans auto-stop when you hit your time limit — you don't pay for idle overnight hours. Your 1,000 ticket/day workflow that was costing $5,400–$8,100/month now runs at a flat, predictable monthly rate.
You break even switching from a $15/million token API to OpenLLM Buddy at about 40 million tokens/month — most support workflows at 500+ tickets/day hit that in the first week.
Ship Your Agent, Not Infrastructure Tickets
You now have everything you need:
FastAPI to receive tickets → Redis to store conversations → OpenLLM Buddy to run the model → tool registry (order DB, refunds, escalations) → output validation → save history
Your agent handles long conversations, calls real tools, validates every output, and escalates when needed.
Your data stays yours. Your model behavior is under your control. Your costs are predictable.
Switch your support agent to OpenLLM Buddy today. One base_url change. Zero token bills. A support backend that grows with you.


